


Model-based Meta-analysis (MBMA) is a quantitative framework that uses pharmacokinetic/pharmacodynamic (PK/PD) and statistical modeling for leveraging external clinical trial efficacy, tolerability, and safety data to inform drug development decisions. MBMA has been used extensively to support developing therapeutic agents for treating a range of diseases including diabetes, autoimmune diseases, osteoporosis, and others.
Last year, we presented our findings at the Population Approach Group in Europe meeting (PAGE) and American Conference on Pharmacometrics (ACOP) on the development of a MBMA comparator model for neuropathic pain (NP). Our goal was to provide a quantitative framework for comparing drugs used to treat diabetic peripheral neuropathy (DPN), post-herpetic neuralgia (PHN), and fibromyalgia.
What is Neuropathic Pain?
Neuropathic pain is a disease of the somatosensory nervous system. This chronic pain syndrome affects 7-10% of the population. Pain is characterized as increased activity and dysfunction of peripheral sensory nerves or nerves within the central nervous system and can result from a variety of conditions including cancer, infection, or stroke.
DPN, PHN and Fibromyalgia
Our MBMA studies focused on DPN, PHN and fibromyalgia, three common NP conditions. DPN arises from uncontrolled, high blood sugar levels damaging nerves on the surface of the skin. The extremely painful condition affects approximately 50% of patients with Type II diabetes and can lead to neuropathic ulcers and amputations.
PHN results in burning, gnawing sensations and hypersensitivity of affected areas. It results from viral damage to nerve cells after a shingles infection and mostly occurs in adults over the age of 60.
Fibromyalgia is a common chronic pain condition which affects an estimated 10 million individuals in the US and 3-6% of the world’s population. This condition is characterized by widespread musculoskeletal pain and tenderness accompanied by fatigue, sleep, memory, and mood issues. It is usually diagnosed between the ages of 20 to 50 years and is more prevalent in women with 75-90% of fibromyalgia patients being female.
All Pain is Not Created Equally
Treatment of chronic, non-cancer pain conditions, such as DPN, PHN, and fibromyalgia, poses a significant challenge. The treatment focuses on improving the patients’ quality of life. However, patients respond poorly to opioids or traditional analgesics. NP is treated with medications with varying mechanisms of action, efficacy, and tolerability profiles. Several classes of drugs that have been developed for other indications, e.g. , anti-epileptic drugs and tricyclic anti-depressants, are used to treat NP. Some common medications used include the α2 delta class of anti-epileptics, gabapentin and pregabalin, and duloxetine, a serotonin reuptake inhibitor. With the rise in opioid addiction, physicians use these low-addiction liability classes of drugs before turning to opioids.
All pain is not created equally – different pain mechanisms require different experimental clinical models. Patient factors contribute to the challenge of developing NP drugs. Pain is a subjective experience. Each NP patient has a unique experience depending how their brain processes the quality, intensity, and location of their pain. This will affect patient reported outcomes and contributes to the large placebo effects often observed in NP drug trials.
Trial design also presents a critical challenge for selecting the appropriate methods of evaluating drug-induced reduction of pain intensity– e.g. Visual Analogue Scale, Numerical Rating Scale, etc. Other issues include the lack of active comparators to controls and the impact on efficacy readouts by trial design elements and treatment duration.
Using MBMA to Overcome the Challenges of Neuropathic Drug Development
As a quantitative framework that uses PK/PD and statistical modeling for leveraging external data to inform drug development decisions, MBMA can help chip away at these challenges. We leveraged MBMA for NP to position ourselves for the future, to start gathering data, and to understand the competitive landscape earlier in the development cycle.
MBMA can translate between different measures of pain intensity, pain relief, and responder rates and between short-term and long-term treatment durations. It also allows the opportunity to utilize more data by including trials where treatment effects are evaluated head to head and can leverage indirect comparisons across trials. Important considerations for using MBMA methodology include the type and availability of dose-response, time course information, and covariate distribution data to best inform future inclusion and exclusion criteria, and how to interpret the results.
Network Diagram of DPN, PHN and Fibromyalgia Analysis Datasets
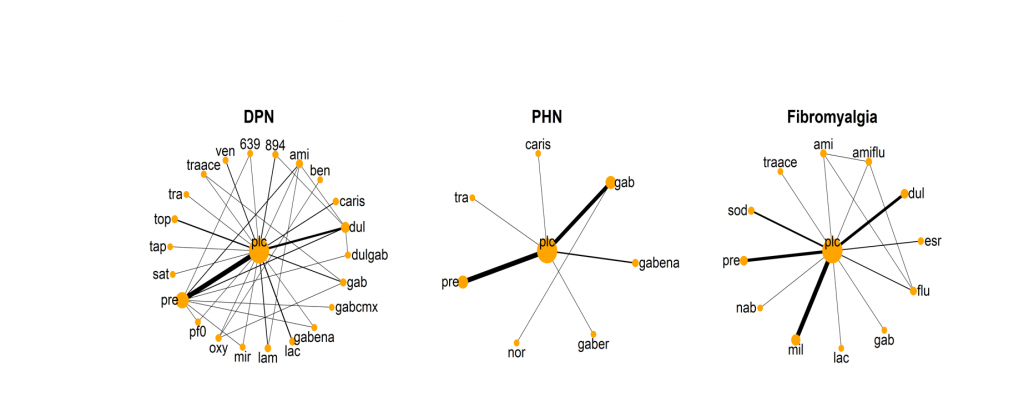
MBMA uses summary level aggregate trial data and fits all data into one model. Data can be leveraged from each indication in the full model. Each node is a drug. Direct comparisons between drugs within a trial are represented by lines. The width of the line is proportional to the number of studies.
Our approach to MBMA for DPN, PHN, and fibromyalgia included the following:
- The use of Clinical Trial Outcomes Databases focused specifically on these indications. The outcomes databases were developed from systematic literature reviews based on predefined inclusion/exclusion criteria,
- Endpoints of average pain change from baseline, and responder rate for 30% (PID30) and 50% (PID50) reduction in pain, which are the FDA recommendations for measuring NP efficacy, and
- Age, race, baseline pain score, disease duration, imputation method, trial year, region, and treatment duration were covariates.
MBMA Comparator Model Key Findings
Our MBMA analysis gathered information that can inform developing more effective NP treatments. First, we showed that the placebo response varies across indications – a lower placebo response was seen for fibromyalgia compared to DPN, PHN for the responder rate endpoint. In addition, at label doses the drug effect compared to the placebo response is about half or less, even for approved drugs used specifically for DPN.
We also improved the model by estimating different potency parameters for duloxetine in fibromyalgia and DPN – the average pain model estimated higher duloxetine potency for fibromyalgia versus DPN. These results correlate well with the FDA guidance for duloxetine, which recommends different starting doses for fibromyalgia and DPN.
In the average pain endpoint model, potential covariate effects were identified including mean age, mean disease duration, and mean baseline score. This information will help inform inclusion/exclusion criteria for future trials.
総括
Employing MBMA methodologies can support the future development of novel drugs to treat DPN, PHN, and fibromyalgia in multiple ways:
- Although there are approved drugs to treat NP, most exhibit small improvements compared to placebo. This presents an opportunity for continued identification of novel treatments and therapies.
- NP drugs perform differently in different indications, and the placebo effect is different. This will allow us to target particular NP indications with more confidence and increase the probability of success.
- The order of standard of care can be ranked, and our novel therapies can be compared for efficacy and safety potential. This will inform go/no-go decisions and obtain proof of concepts especially where active comparator arms are not included in this trial design.
In conclusion, MBMA provides valuable information on treatment and placebo effects. Employ MBMA as a tool to better understand your competition and your novel compound.
To learn more about how we used MBMA to support the development of drugs for DPN, PHN, and fibromyalgia, watch our webinar.
